{kind=link}
“`html
Today, we’re excited to announce the availability of Llama 2 inference and fine-tuning support on AWS Trainium and AWS Inferentia instances in Amazon SageMaker JumpStart. Using AWS Trainium and Inferentia based instances, through SageMaker, can help users lower fine-tuning costs by up to 50%, and lower deployment costs by 4.7x, while lowering per token latency. Llama 2 is an auto-regressive generative text language model that uses an optimized transformer architecture. As a publicly available model, Llama 2 is designed for many NLP tasks such as text classification, sentiment analysis, language translation, language modeling, text generation, and dialogue systems. Fine-tuning and deploying LLMs, like Llama 2, can become costly or challenging to meet real time performance to deliver good customer experience. Trainium and AWS Inferentia, enabled by the AWS Neuron software development kit (SDK), offer a high-performance, and cost effective option for training and inference of Llama 2 models.
In this post, we demonstrate how to deploy and fine-tune Llama 2 on Trainium and AWS Inferentia instances in SageMaker JumpStart.
Solution overview
In this blog, we will walk through the following scenarios :
Deploy Llama 2 on AWS Inferentia instances in both the Amazon SageMaker Studio UI, with a one-click deployment experience, and the SageMaker Python SDK.
Fine-tune Llama 2 on Trainium instances in both the SageMaker Studio UI and the SageMaker Python SDK.
Compare the performance of the fine-tuned Llama 2 model with that of pre-trained model to show the effectiveness of fine-tuning.
To get hands on, see the GitHub example notebook.
Deploy Llama 2 on AWS Inferentia instances using the SageMaker Studio UI and the Python SDK
In this section, we demonstrate how to deploy Llama 2 on AWS Inferentia instances using the SageMaker Studio UI for a one-click deployment and the Python SDK.
Discover the Llama 2 model on the SageMaker Studio UI
SageMaker JumpStart provides access to both publicly available and proprietary foundation models. Foundation models are onboarded and maintained from third-party and proprietary providers. As such, they are released under different licenses as designated by the model source. Be sure to review the license for any foundation model that you use. You are responsible for reviewing and complying with any applicable license terms and making sure they are acceptable for your use case before downloading or using the content.
You can access the Llama 2 foundation models through SageMaker JumpStart in the SageMaker Studio UI and the SageMaker Python SDK. In this section, we go over how to discover the models in SageMaker Studio.
SageMaker Studio is an integrated development environment (IDE) that provides a single web-based visual interface where you can access purpose-built tools to perform all machine learning (ML) development steps, from preparing data to building, training, and deploying your ML models. For more details on how to get started and set up SageMaker Studio, refer to Amazon SageMaker Studio.
After you’re in SageMaker Studio, you can access SageMaker JumpStart, which contains pre-trained models, notebooks, and prebuilt solutions, under Prebuilt and automated solutions. For more detailed information on how to access proprietary models, refer to Use proprietary foundation models from Amazon SageMaker JumpStart in Amazon SageMaker Studio.
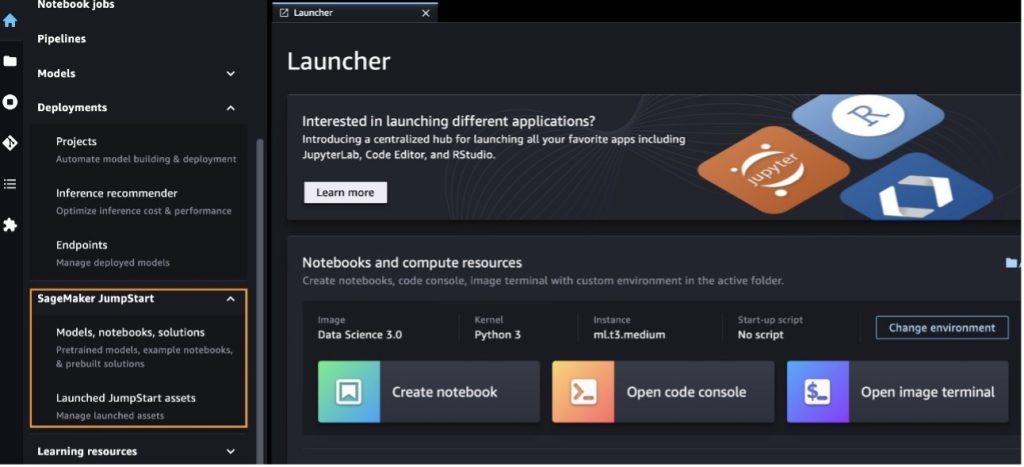
From the SageMaker JumpStart landing page, you can browse for solutions, models, notebooks, and other resources.
If you don’t see the Llama 2 models, update your SageMaker Studio version by shutting down and restarting. For more information about version updates, refer to Shut down and Update Studio Classic Apps.
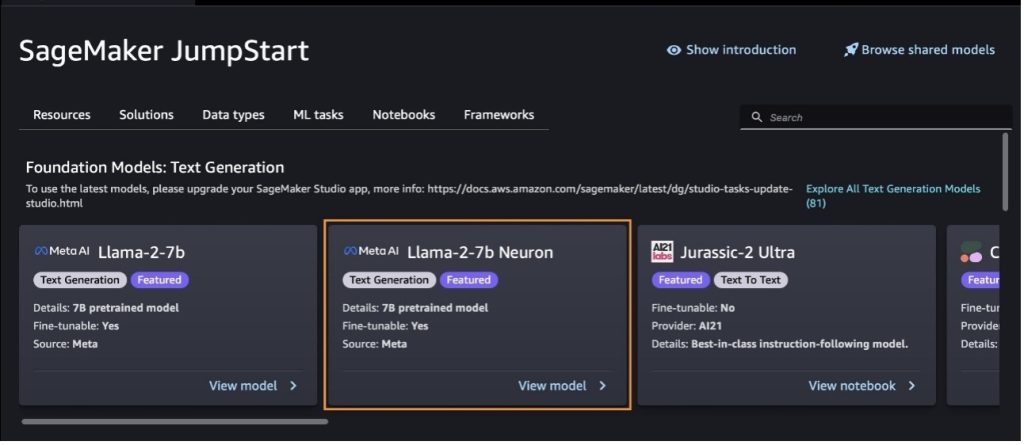
You can also find other model variants by choosing Explore All Text Generation Models or searching for llama or neuron in the search box. You will be able to view the Llama 2 Neuron models on this page.
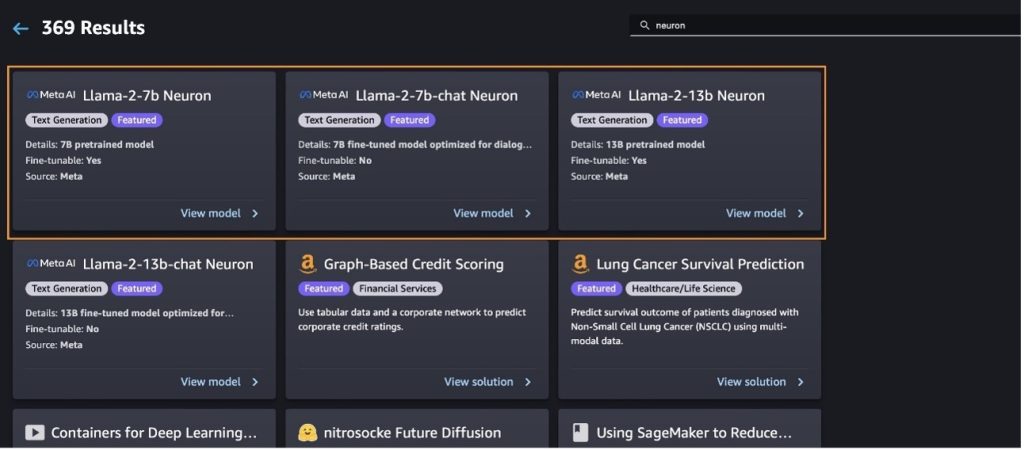
Deploy the Llama-2-13b model with SageMaker Jumpstart
You can choose the model card to view details about the model such as license, data used to train, and how to use it. You can also find two buttons, Deploy and Open notebook, which help you use the model using this no-code example.
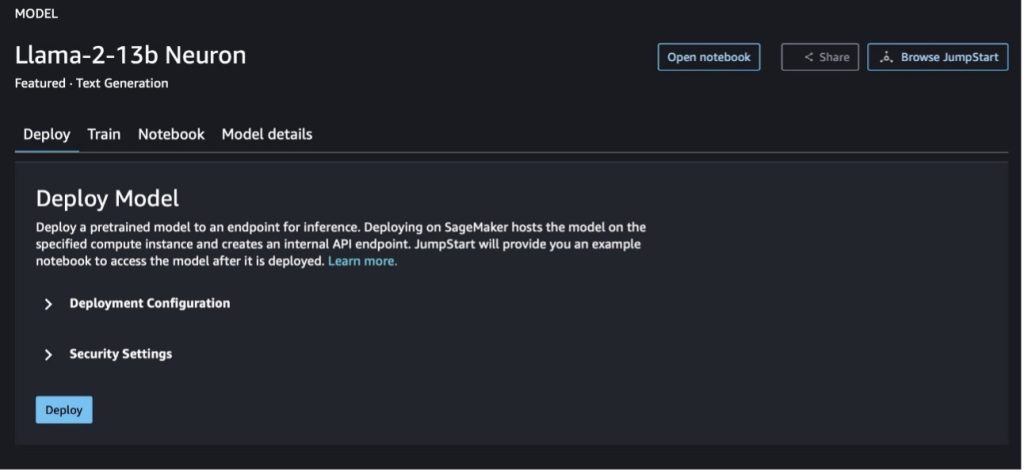
When you choose either button, a pop-up will show the End User License Agreement and Acceptable Use Policy (AUP) for you to acknowledge.
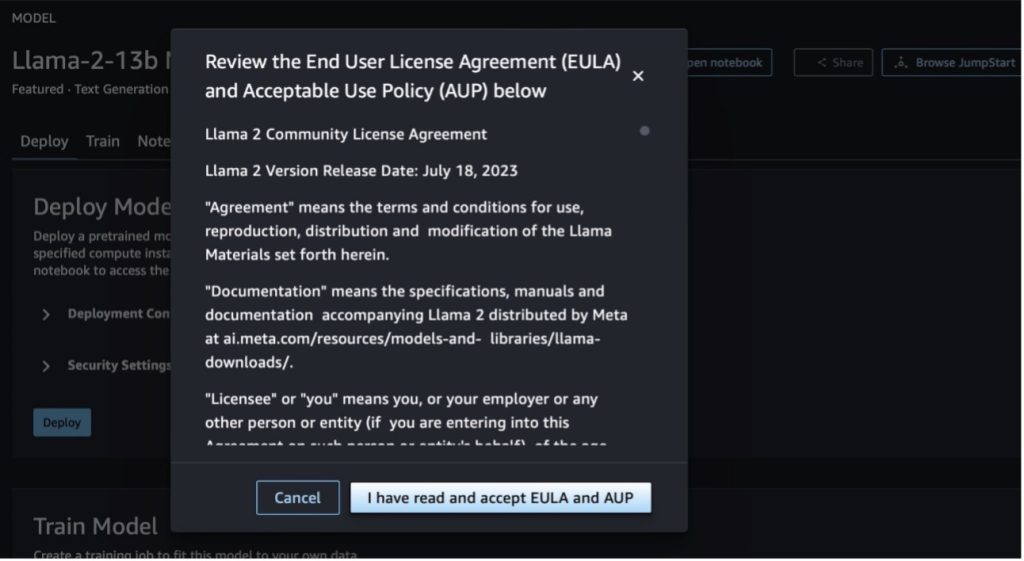
After you acknowledge the policies, you can deploy the endpoint of the model and use it via the steps in the next section.
Deploy the Llama 2 Neuron model via the Python SDK
When you choose Deploy and acknowledge the terms, model deployment will start. Alternatively, you can deploy through the example notebook by choosing Open notebook. The example notebook provides end-to-end guidance on how to deploy the model for inference and clean up resources.
To deploy or fine-tune a model on Trainium or AWS Inferentia instances, you first need to call PyTorch Neuron (torch-neuronx) to compile the model into a Neuron-specific graph, which will optimize it for Inferentia’s NeuronCores. Users can instruct the compiler to optimize for lowest latency or highest throughput, depending on the objectives of the application. In JumpStart, we pre-compiled the Neuron graphs for a variety of configurations, to allow users to sip compilation steps, enabling faster fine-tuning and deploying models.
Note that the Neuron pre-compiled graph is created based on a specific version of the Neuron Compiler version.
There are two ways to deploy LIama 2 on AWS Inferentia-based instances. The first method utilizes the pre-built configuration, and allows you to deploy the model in just two lines of code. In the second, you have greater control over the configuration. Let’s start with the first method, with the pre-built configuration, and use the pre-trained Llama 2 13B Neuron Model, as an example. The following code shows how to deploy Llama 13B with just two lines:
from sagemaker.jumpstart.model import JumpStartModel
model_id = “meta-textgenerationneuron-llama-2-13b”
model = JumpStartModel(model_id=model_id)
pretrained_predictor = model.deploy(accept_eula=False) ## To set ‘accept_eula’ to be True to deploy
To perform inference on these models, you need to specify the argument accept_eula to be True as part of the model.deploy() call. Setting this argument to be true, acknowledges you have read and accepted the EULA of the model. The EULA can be found in the model card description or from the Meta website.
The default instance type for Llama 2 13B is ml.inf2.8xlarge. You can also try other supported models IDs:
meta-textgenerationneuron-llama-2-7b
meta-textgenerationneuron-llama-2-7b-f (chat model)
meta-textgenerationneuron-llama-2-13b-f (chat model)
Alternatively, if you want have more control of the deployment configurations, such as context length, tensor parallel degree, and maximum rolling batch size, you can modify them via environmental variables, as demonstrated in this section. The underlying Deep Learning Container (DLC) of the deployment is the Large Model Inference (LMI) NeuronX DLC. The environmental variables are as follows:
OPTION_N_POSITIONS – The maximum numbers of input and output tokens. For example, if you compile the model with OPTION_N_POSITIONS as 512, then you can use an input token of 128 (input prompt size) with a maximum output token of 384 (the total of the input and output tokens has to be 512). For the maximum output token, any value below 384 is fine, but you can’t go beyond it (for example, input 256 and output 512).
OPTION_TENSOR_PARALLEL_DEGREE – The number of NeuronCores to load the model in AWS Inferentia instances.
OPTION_MAX_ROLLING_BATCH_SIZE – The maximum batch size for concurrent requests.
OPTION_DTYPE – The date type to load the model.
The compilation of Neuron graph depends on the context length (OPTION_N_POSITIONS), tensor parallel degree (OPTION_TENSOR_PARALLEL_DEGREE), maximum batch size (OPTION_MAX_ROLLING_BATCH_SIZE), and data type (OPTION_DTYPE) to load the model. SageMaker JumpStart has pre-compiled Neuron graphs for a variety of configurations for the preceding parameters to avoid runtime compilation. The configurations of pre-compiled graphs are listed in the following table. As long as the environmental variables fall into one of the following categories, compilation of Neuron graphs will be skipped.
- LIama-2 7B and LIama-2 7B Chat
- LIama-2 13B and LIama-2 13B Chat
| Instance type | OPTION_N_POSITIONS | OPTION_MAX_ROLLING_BATCH_SIZE | OPTION_TENSOR_PARALLEL_DEGREE | OPTION_DTYPE |
| ml.inf2.xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.8xlarge | 2048 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
| ml.inf2.8xlarge | 1024 | 1 | 2 | fp16 |
| ml.inf2.24xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.24xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 2048 | 4 | 4 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 8 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 12 | fp16 |
| ml.inf2.48xlarge | 4096 | 4 | 24 | fp16 |
The following is an example of deploying Llama 2 13B and setting all the available configurations.
from sagemaker.jumpstart.model import JumpStartModel
model_id = “meta-textgenerationneuron-llama-2-13b-f”
model = JumpStartModel(
model_id=model_id,
env={
“OPTION_DTYPE”: “fp16”,
“OPTION_N_POSITIONS”: “4096”,
“OPTION_TENSOR_PARALLEL_DEGREE”: “12”,
“OPTION_MAX_ROLLING_BATCH_SIZE”: “4”,
},
instance_type=”ml.inf2.24xlarge”
)
pretrained_predictor = model.deploy(accept_eula=False) ## To set ‘accept_eula’ to be True to deploy
Now that we have deployed the Llama-2-13b model, we can run inference with it by invoking the endpoint. The following code snippet demonstrates using the supported inference parameters to control text generation:
max_length – The model generates text until the output length (which includes the input context length) reaches max_length. If specified, it must be a positive integer.
max_new_tokens – The model generates text until the output length (excluding the input context length) reaches max_new_tokens. If specified, it must be a positive integer.
num_beams – This indicates the number of beams used in the greedy search. If specified, it must be an integer greater than or equal to num_return_sequences.
no_repeat_ngram_size – The model ensures that a sequence of words of no_repeat_ngram_size is not repeated in the output sequence. If specified, it must be a positive integer greater than 1.
temperature – This controls the randomness in the output. A higher temperature results in an output sequence with low-probability words; a lower temperature results in an output sequence with high-probability words. If temperature equals 0, it results in greedy decoding. If specified, it must be a positive float.
early_stopping – If True, text generation is finished when all beam hypotheses reach the end of the sentence token. If specified, it must be Boolean.
do_sample – If True, the model samples the next word as per the likelihood. If specified, it must be Boolean.
top_k – In each step of text generation, the model samples from only the top_k most likely words. If specified, it must be a positive integer.
top_p – In each step of text generation, the model samples from the smallest possible set of words with a cumulative probability of top_p. If specified, it must be a float between 0–1.
stop – If specified, it must be a list of strings. Text generation stops if any one of the specified strings is generated.
The following code shows an example:
payload = {
“inputs”: “I believe the meaning of life is”,
“parameters”: {
“max_new_tokens”: 64,
“top_p”: 0.9,
“temperature”: 0.6,
},
}
response = pretrained_predictor.predict(payload)
Output:
I believe the meaning of life is
> to be happy. I believe that happiness is a choice. I believe that happiness
is a state of mind. I believe that happiness is a state of being. I believe that
happiness is a state of being. I believe that happiness is a state of being. I
believe that happiness is a state of being. I believe
For more information on the parameters in the payload, refer to Detailed parameters.
You can also explore the implementation of the parameters in the notebook to add more information about the link of the notebook