{kind=link}
This is the eleventh part of the Flare-On 6 CTF WriteUp Series.
11 – vv_max
The challenge reads
Hey, at least its not subleq.
Subleq is an esoteric language. The program grammar consists of a single instruction “Subtract and Branch if Less Than or Equal”. The final challenge of Flare-on 5 deal with reversing such a binary. You can read more on it here.
Different from previous year’s, this year’s penultimate challenge is not about Subleq but rather about a reversing a small VM which uses AVX instructions for its operation.
For running the challenge binary our processor must support AVX. Nearly all Intel/AMD CPU released within the last 7-8 years supports AVX. In case our CPU doesn’t support AVX we may still be able to run it using Intel Software Development Emulator (SDE). Intel SDE uses Pin – a DBI tool to “run” the binary. Any instruction which is not supported by the host CPU will be emulated by SDE.
Let’s go back to the challenge. From the main function there’s a call to a function which I have named is_avx_supported.
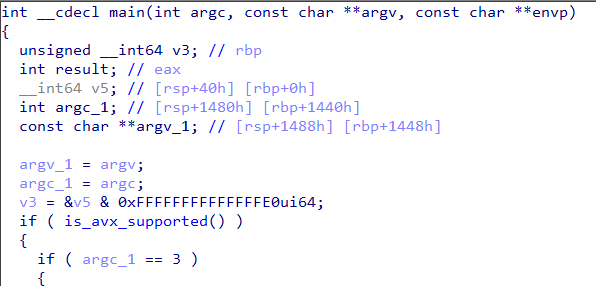 Figure 1: Call to is_avx_supported
Figure 1: Call to is_avx_supported
This function tests the presense of AVX support on the host CPU as shown in Figure 2.
 Figure 2: Checking AVX support
Figure 2: Checking AVX support
If we run the binary it just prints out “Nope!” and then quits. We need to provide two command line arguments.
 Figure 3: Checking length of the arguments
Figure 3: Checking length of the arguments
As we can see in Figure 3, the length of the first argument must lie between 4 and 32. The second argument must be 32 chars in length. If both of these checks succeed it goes on to execute the main code.
 Figure 4: The main code
Figure 4: The main code
The second parameter to the check function is the first command line argument. Going into check we can see that after it prints “That is correct” it compares arg1 with “FLARE2019” as in Figure 5.
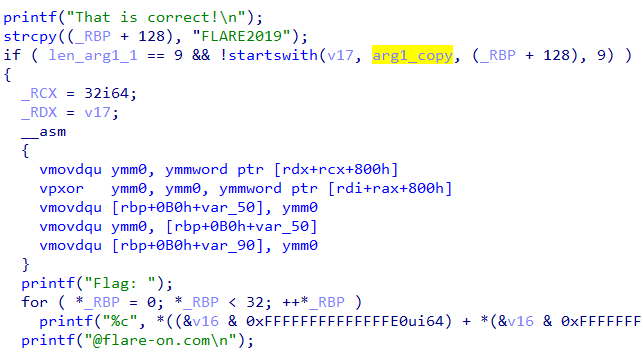 Figure 5: Arg1 must equal FLARE2019
Figure 5: Arg1 must equal FLARE2019
If arg1 equals “FLARE2019” it goes on to print Flag: “. From this we infer the first command line argument must be “FLARE2019”. The challenge is like a typical keygenme where it checks name-serial pairs. We need to calculate the serial for a then name “FLARE2019”.
We can already see a few AVX instructions in the check function. The logic of the challenge is implemented by such instructions. Going through the list of functions in IDA, we can find several functions with AVX instructions in them. These functions are actually handlers implementing a particular opcode of the VM.
 Figure 6: setup_handlers
Figure 6: setup_handlers
In the setup_handlers function, it fills an array with the addresses of the handler functions. In total there are 24 handler functions for 24 VM instructions. The bytecode of the VM is of size 0x5FB as evident from the qmemcpy call.
 FIgure 7: The VM bytecode
FIgure 7: The VM bytecode
The VM instructions themselves are of varying length. For example, the VM instruction which has the opcode 0 is just 1 byte in size whereas the one with opcode 1 is 4 bytes in size. We can obtain the lengths of the instructions by analyzing the decompiled code of the handlers.
 Figure 7: Handler for opcode 0
Figure 7: Handler for opcode 0
a1[384] stores the Program Counter (PC) of the VM. In opcode_00 we can see its incremented by 1 which corresponds to the length of the instruction. Similarly, in opcode_01 , PC is incremented by 4 as shown in Figure 8.
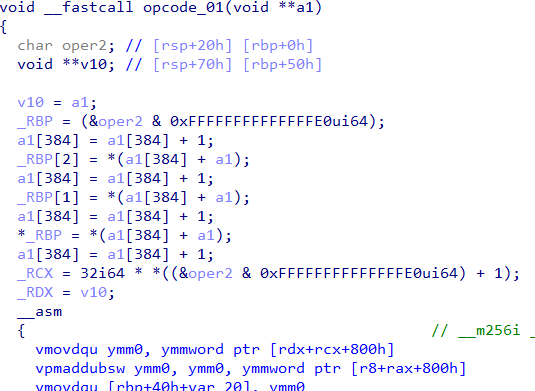 Figure 8: Handler for opcode 01
Figure 8: Handler for opcode 01
Out of the 24 instructions implemented by the VM, opcode_00 has a length of 1 byte and opcode_11 has a size of 34 bytes. Remaining 22 opcodes have a length of 4 bytes. Also the VM has no control flow instructions i.e. there is no instruction for direct/indirect calls/jumps. Knowing the length of the instructions we can code a small tool to print the disassemble the bytecode.
bytecode = [] # The entire bytecode goes here
arg1 = bytearray(‘FLARE2019’)
arg2 = bytearray(‘A’*32)
bytecode[3:3+len(arg1)] = arg1
bytecode[37:37+len(arg2)] = arg2
ip = 0
ins_len_map = {
0x00: 1,
0x01: 4,
0x02: 4,
0x03: 4,
0x04: 4,
0x05: 4,
0x07: 4,
0x0B: 4,
0x11: 2+32,
0…
while ip < len(bytecode):
ins = bytecode[ip]
if ins in ins_len_map:
i_len = ins_len_map[ins]
print ‘opcode_{:02X}’.format(ins)
ip += i_len
elif ins == 0xff:
break
else:
print ‘[!] Unknown opcode’
break
Running the script we will obtain sequential list of instructions executed by the VM. The output of the script can be found here. A close look at the script reveals that the following 10 opcodes are missing
opcode_06opcode_08opcode_09opcode_0Aopcode_0Copcode_0Dopcode_0Eopcode_0Fopcode_10opcode_17
Thus out of the 24 supported VM instructions only 14 are executed. Rest of the 10 instructions are redundant and need not be analyzed.
Using compiler intrinsics
To understand what an opcode does we need to convert it to a C like representation. The Microsoft C++ compiler supports intrinsics which can be used to represent an AVX instruction. We can use the Intel Intrinsics Guide as a reference to find the corresponding intrinsic for an AVX instruction.
Out of the 14 instructions, opcode_00 is only executed once and its purpose is just to zero out the memory location [rcx+rax+800h] (Figure 7). The other opcodes represented using compiler intrinsics are as follows.
// Vertical multiply
void opcode_01(int dest, int a, int b)
{
_mm256_storeu_si256(&scratch[dest], _mm256_maddubs_epi16(scratch[a], scratch[b]));
}
// Multiply packed signed
void opcode_02(int dest, int a, int b)
{
_mm256_storeu_si256(&scratch[dest], _mm256_madd_epi16(scratch[a], scratch[b]));
}
// Xor
void opcode_03(int dest, int a, int b)
{
_mm256_storeu_si256(&scratch[dest], _mm256_xor_si256 (scratch[a], scratch[b]));
}
// Or
void opcode_04(int dest, int a, int b)
{
_mm256_storeu_si256(&scratch[dest], _mm256_or_si256(scratch[a], scratch[b]));
}
// And
void opcode_05(int dest, int a, int b)
{
_mm256_storeu_si256(&scratch[dest], _mm256_and_si256 (scratch[a], scratch[b]));
}
// Add
void opcode_07(int dest, int a, int b)
{
_mm256_storeu_si256(&scratch[dest], _mm256_add_epi8(scratch[a], scratch[b]));
}
// Add
void opcode_0B(int dest, int a, int b)
{
_mm256_storeu_si256(&scratch[dest], _mm256_add_epi32(scratch[a], scratch[b]));
}
// Copy
void opcode_11(int dest, BYTE *v)
{
_mm256_storeu_si256(&scratch[dest], _mm256_loadu_si256((__m256i*)v));
}
//Shift right
void opcode_12(int dest, int a, int imm8)
{
_mm256_storeu_si256(&scratch[dest], _mm256_srli_epi32 (scratch[a], imm8));
}
// Shift left
void opcode_13(int dest, int a, int count)
{
_mm256_storeu_si256(&scratch[dest], _mm256_slli_epi32(scratch[a], count));
}
// Shuffle
void opcode_14(int dest, int a, int b)
{
_mm256_storeu_si256(&scratch[dest], _mm256_shuffle_epi8(scratch[a], scratch[b]));
}
//permute
void opcode_15(int dest, int a, int b)
{
_mm256_storeu_si256(&scratch[dest], _mm256_permutevar8x32_epi32(scratch[a], scratch[b]));
}
// Compare
void opcode_16(int dest, int a, int b)
{
_mm256_storeu_si256(&scratch[dest], _mm256_cmpeq_epi8(scratch[a], scratch[b]));
}
Inferring the VM algorithm
Among the 13 opcodes, there is just a single opcode which compares two values – opcode_16 Let’s set a breakpoint on the vcmpeqb instruction in opcode_16 and debug the program with a proper arguments like vvmax.exe FLARE2019 AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA.
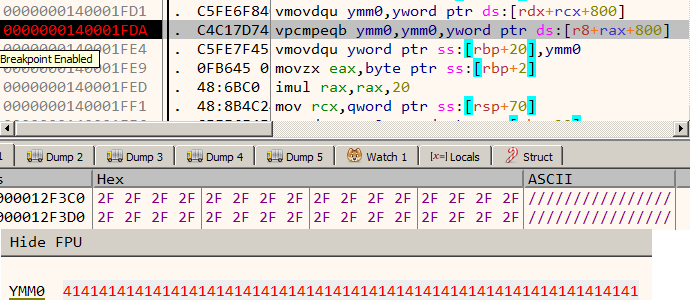 Figure 9: Our input is compared with the forward slash character
Figure 9: Our input is compared with the forward slash character
Our input (32 A’s) is compared with 32 forward slash characters. Lets keep a note of this.
Now back in the check function there is another vcmpeqb instruction that compares two values as shown in Figure 10.
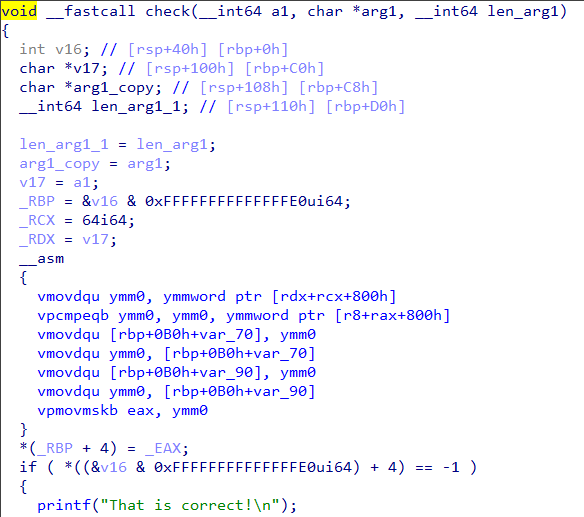 Figure 10: Another vcmpeqb instruction
Figure 10: Another vcmpeqb instruction
Let’s use the debugger to find what values are being compared.
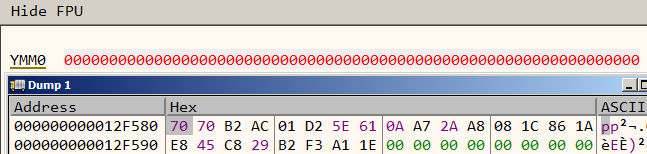 Figure 11: First attempt
Figure 11: First attempt
It compares the 256 bit value 70 70 B2 AC 01 D2 5E 61 0A A7 2A A8 08 1C 86 1A E8 45 C8 29 B2 F3 A1 1E 00 00 00 00 00 00 00 00 with zero.
Let’s try running with a slightly different input say vvmax.exe FLARE2019 BAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA.
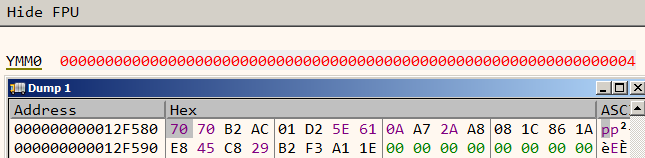 Figure 12: Second attempt
Figure 12: Second attempt
In our second attempt, the 256 bit value in memory doesn’t change. However the value in ymm0 has changed to 4. By more attempts, we can infer the 256 bit value in memory is calculated from the first command line argument (FLARE2019) which is fixed. The value in ymm0 register is calculated from the second argument.
For a change, let’s run using the following argument vmax.exe FLARE2019 CCCCAAAAAAAAAAAAAAAAAAAAAAAAAAAA
 Figure 13: Third attempt
Figure 13: Third attempt
We have modified the first 4 characters of our input. Corresponding to that only 3 bytes in ymm0 has changed. Let’s recap what we have found so far
There is a comparison against the / character4 bytes of input correspond to 3 bytes after some calculationA buffer of 32’A after calculation becomes 32 zeroes
This strongly suggests the calculation implemented in the VM on the second argument is nothing but Base64.
Getting the flag
Let’s try base64 encoding the 256 bit value 70 70 B2 AC 01 D2 5E 61 0A A7 2A A8 08 1C 86 1A E8 45 C8 29 B2 F3 A1 1E 00 00 00 00 00 00 00 00 neglecting the trailing zeroes.
>>> v = ’70 70 B2 AC 01 D2 5E 61 0A A7 2A A8 08 1C 86 1A E8 45 C8 29 B2 F3 A1 1E’
>>> v = v.replace(‘ ‘, ”)
>>> v = v.decode(‘hex’).encode(‘base64’)
>>> v
‘cHCyrAHSXmEKpyqoCByGGuhFyCmy86Ee\n’
Running the program using the base64 encoded value as the second argument, we get the flag.
 Figure 14: The flag!
Figure 14: The flag!
Flag: [email protected]