
Introduction
Let’s say you have a talented friend who can recognize patterns, like determining whether an image contains a cat or a dog. Now, this friend has a precise way of doing things, like he has a dictionary in his head. But, here’s the problem: this encyclopedia is huge and requires significant time and effort to use.
Consider simplifying the process, like converting that big encyclopedia into a convenient cheat sheet. This is similar to the way model quantization works for clever computer programs. It takes these intelligent programs, which can be excessively large and sluggish, and streamlines them, making them faster and less demanding on the machine. How does this work? Well, it’s similar to rounding off difficult figures. If the numbers in your friend’s encyclopedia were really extensive and comprehensive, you can decide to simplify them to speed up the process. Model quantization techniques, reduce the ‘numbers’ that the computer uses to recognize objects.
So why should we care? Imagine that your friend is helping you on your smartphone. You want it to be able to recognize objects fast without taking up too much battery or space. Model quantization makes your phone’s brain operate more effectively, similar to a clever friend who can quickly identify things without having to consult a large encyclopedia every time.
This article was published as a part of the Data Science Blogathon.
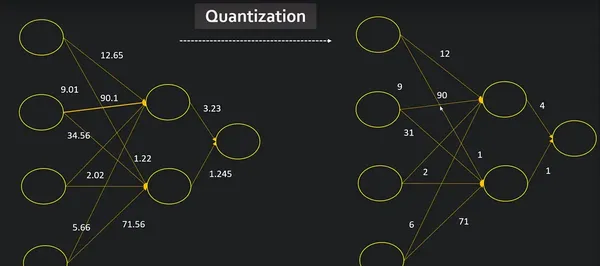
What is Model Quantization?
Quantization is a method that can allow models to run faster and use less memory. By converting 32-bit floating-point numbers (float32 data type) to lower-precision formats such as 8-bit integers (int8 data type), we can reduce the computational requirements of our model.
Quantization is the process of reducing the precision of a model’s weights and activations from floating-point to smaller bit-width representations. It aims to increase the adaptability of the model for deployment on constrained devices such as smartphones and embedded systems by reducing memory footprint and increasing inference speed.
… (remaining content has been maintained with HTML tags)